编码智能体:编码智能体基础设施
Embedding 介绍
AI概念
了解如何使用向量技术构建AI应用
向量技术是构建AI应用的核心组成部分。本文将介绍向量及其生成、使用和在Postgres中的存储方式。
什么是向量?
在处理非结构化数据时,一个常见的目标是将其转化为更易于分析和检索的结构化格式。这种转化可以通过“向量”实现,向量是包含一组浮点数的向量,代表数据的特征或维度。例如,像“牛跳过月亮”这样的句子可以表示为一个类似这样的向量:[0.5, 0.3, 0.1]。
向量的优点在于它们可以衡量不同文本片段之间的相似度。通过计算两个向量之间的距离,我们可以评估它们的相关性——距离越小,相似度越大,反之亦然。这一特性特别有用,因为它使向量能够捕捉文本的内在含义。
例如,考虑以下三句话:
- 句子1:“牛跳过月亮。”
- 句子2:“牛跳跃在天体之上。”
- 句子3:“我喜欢吃煎饼。”
你可以按照以下步骤确定最相似的句子:
- 为每个句子生成向量。假设这些值代表实际向量:
- 句子1的向量 → [0.5, 0.3, 0.1]
- 句子2的向量 → [0.6, 0.29, 0.12]
- 句子3的向量 → [0.1, -0.2, 0.4]
-
计算所有向量对(1&2, 2&3, 1&3)之间的距离。
-
确定距离最短的向量对。
当我们应用这一过程时,句子1和句子2这两句都涉及跳跃的牛,根据距离计算,它们可能会被识别为最相关的。
向量相似性搜索
将数据转化为向量并计算一个或多个项目之间的相似性被称为向量搜索或相似性搜索。这个过程有广泛的应用,包括:
- 信息检索:通过将用户查询表示为向量,我们可以基于查询背后的意义执行更准确的搜索,从而检索到更相关的信息。
- 自然语言处理:向量捕捉文本的本质,使其成为文本分类和情感分析等任务的优秀工具。
- 推荐系统:利用向量相似性,我们可以推荐与给定项目相似的项目,无论是电影、产品、书籍等。这个技术允许我们创建更个性化和相关的推荐。
- 异常检测:通过确定数据集中项目之间的相似性,我们可以识别出不符合模式的异常项。这在许多领域中都至关重要,从网络安全到质量控制。
距离度量
向量相似性搜索通过计算数据点之间的距离来衡量它们的相似性。计算数据点之间的距离有助于我们理解它们之间的关系。距离可以通过不同的度量方式计算。一些常见的距离度量包括:
- 欧几里得距离(L2):通常被称为“普通”距离,用尺子测量的距离。
- 曼哈顿距离(L1):也称为“出租车”或“城市街区”距离。
- 余弦距离:计算两个向量之间角度的余弦。
pgvector扩展还支持其他距离度量,如汉明距离和雅卡尔距离。
不同的距离度量适用于不同的任务,具体取决于数据的性质和你关注的特定关系。例如,余弦相似性常用于文本分析。
生成向量
生成向量的一种常见方法是使用LLM API,例如OpenAI的向量API。该API允许你将文本字符串输入到API端点,然后返回相应的向量。“牛跳过月亮”是一个具有3个维度的简单示例。大多数向量模型生成的向量具有更多的维度。OpenAI最新且性能最好的向量模型text-embedding-3-small和text-embedding-3-large默认生成1536和3072维度的向量。
以下是如何使用OpenAI的text-embedding-3-small模型生成向量的示例:
curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-small"
}'
注意:运行上述命令需要一个OpenAI API密钥,必须从OpenAI获取。
成功执行后,你将收到类似以下的响应:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
... (为了简洁省略)
-4.547132266452536e-05,
-0.024047505110502243
],
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
要了解更多关于OpenAI向量的信息,请参见向量。 这里,你会找到一个从Amazon美食评论数据集(CSV文件)获取向量的示例。参见获取向量。
你可以使用许多向量模型,例如由Mistral AI、Cohere、Hugging Face等提供的模型。AI工具如LangChain提供了处理各种模型的接口和集成。参见LangChain: 文本向量模型。你还会在LangChain网站上找到Neon Postgres指南和Class NeonPostgres,它提供了与Neon Postgres数据库交互的接口。
在Postgres中存储向量向量
Neon支持pgvector Postgres扩展,这使得可以直接在Postgres数据库中存储和检索向量向量。在构建AI应用时,安装该扩展消除了需要扩展架构以包含单独向量存储的需求。 从Neon SQL编辑器或任何连接到你的Neon Postgres数据库的SQL客户端运行以下CREATE EXTENSION语句即可安装pgvector扩展:
CREATE EXTENSION vector;
安装 pgvector 扩展后,你可以创建一个表来存储你的向量。例如,你可以定义一个类似如下的表来存储你的向量:
CREATE TABLE items(id BIGSERIAL PRIMARY KEY, embedding VECTOR(1536));
要将向量添加到表中,你可以插入如下数据:
INSERT INTO items(embedding) VALUES ('[
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
]');
有关使用pgvector的详细信息,请参阅我们的指南:pgvector扩展。
查询算法
TF-IDF
TF-IDF 是一种用于评估文档中关键词重要性的方法,它通过计算关键词在文档中的频率和在整个文档集合中的逆文档频率来评估关键词的重要性。
变体:c-TF-IDF
https://maartengr.github.io/BERTopic/getting_started/ctfidf/ctfidf.html
c-TF-IDF 和传统的 TF-IDF 之间的关键区别在于它们的应用和分析层次:
传统的 TF-IDF
- 文档级分析:TF-IDF 代表词频-逆文档频率。它是一种统计度量,用于评估单词在文档中的重要性相对于整个文档集(语料库)。
- 计算:
- 词频(TF):测量一个术语 ( t ) 在文档 ( d ) 中出现的频率。
- 逆文档频率(IDF):测量一个术语在所有文档中的重要性。计算公式是 ( \log \left( \frac{N}{n_t} \right) ),其中 ( N ) 是文档总数,( n_t ) 是包含术语 ( t ) 的文档数。
- TF-IDF 得分:TF 和 IDF 的乘积。这个得分随着单词在文档中出现次数的增加而增加,但会被该单词在语料库中频率的增长所抵消。
c-TF-IDF
- 簇/主题级分析:c-TF-IDF 将 TF-IDF 调整为在簇或类别层面上工作,而不是单个文档层面。这种方法在主题建模中特别有用,例如在 BERTopic 中。
- 计算:
- 基于类别的词频(c-TF):每个簇(或类别)被视为单个文档。词频是基于这个合并文档中单词的频率计算的,并且针对主题大小的差异进行标准化。
- 基于类别的逆文档频率(c-IDF):调整以考虑每个类别的平均单词数。计算公式是 ( \log \left( 1 + \frac{A}{f_x} \right) ),其中 ( A ) 是每个类别的平均单词数,( f_x ) 是单词 ( x ) 在所有类别中的频率。
- c-TF-IDF 得分:c-TF 和 c-IDF 的乘积,给出一个单词在特定簇中的重要性相对于其他簇的得分。
c-TF-IDF 的优势
- 更好的主题表示:通过关注文档的簇,c-TF-IDF 强调了一个簇中的文档与其他簇的文档之间的区别。
- 定制和模块化:BERTopic 中的 c-TF-IDF 模型可以进行调优和定制,例如,应用不同的加权方案或减少频繁出现的词。
- 增强的鲁棒性:像 bm25_weighting 和 reduce_frequent_words 这样的选项提供了对通常不会被过滤掉的常见词的额外鲁棒性。
BM25 算法
BM25 是一种基于概率的信息检索算法,用于评估文档与查询之间的相关性。BM25 算法的核心思想是通过计算文档中的关键词与查询中的关键词之间的匹配程度,来评估文档与查询之间的相关性。

TF/IDF 基于相似性,具有内置的 tf 归一化,适用于短字段(如姓名)。详见 Okapi_BM25。 此相似性具有以下选项:
| 选项 | 描述 |
|---|---|
k1 | 控制非线性词频归一化(饱和)。默认值为 1.2。 |
b | 控制文档长度在多大程度上归一化 tf 值。默认值为 0.75。 |
discount_overlaps | 确定在计算规范时是否忽略重叠标记(位置增量为 0 的标记)。默认情况下,此值为 true,即在计算规范时不计算重叠标记。 |
类型名称:BM25
BM25f
介绍 Elasticsearch Relevance Engine™ — 为 AI 变革提供高级搜索能力
Jaccard 相似度
Jaccard 相似度是一种用于计算两个集合之间相似度的方法,它是通过计算两个集合的交集与并集之间的比例来评估它们之间的相似度。
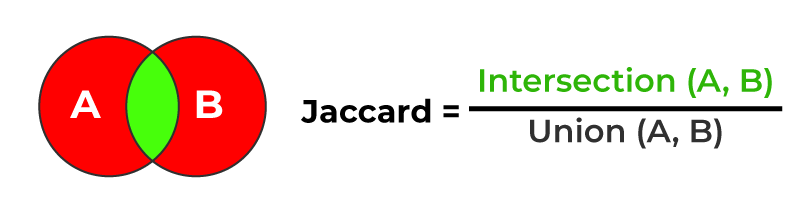
Jaccard 相似度的计算公式如下:
J(A, B) = |A ∩ B| / |A ∪ B|
Kotlin 实现:
fun similarityScore(set1: Set<String>, set2: Set<String>): Double {
val intersectionSize = set1.intersect(set2).size
val unionSize = set1.union(set2).size
return intersectionSize.toDouble() / unionSize
}
TypeScript 实现:
function similarityScore(set1: Set<string>, set2: Set<string>): number {
const intersectionSize: number = [...set1].filter(x => set2.has(x)).length;
const unionSize: number = new Set([...set1, ...set2]).size;
return intersectionSize / unionSize;
}
SPLADE
SPLADE(Sequential Pattern Mining by Limited Area DEcomposition)是一种用于发现序列模式的算法,它通过将序列划分为多个子序列,并在每个子序列上应用频繁模式挖掘算法来发现序列模式。
GitHub: https://github.com/naver/splade
BM42
sentences = "Hello, World - is the starting point in most programming languages"
features = transformer.tokenize(sentences)
# ...
attentions = transformer.auto_model(**features, output_attentions=True).attentions
weights = torch.mean(attentions[-1][0,:,0], axis=0)
# ▲ ▲ ▲ ▲
# │ │ │ └─── [CLS] token is the first one
# │ │ └─────── First item of the batch
# │ └────────── Last transformer layer
# └────────────────────────── Averate all 6 attention heads
for weight, token in zip(weights, tokens):
print(f"{token}: {weight}")
# [CLS] : 0.434 // Filter out the [CLS] token
# hello : 0.039
# , : 0.039
# world : 0.107 // <-- The most important token
# - : 0.033
# is : 0.024
# the : 0.031
# starting : 0.054
# point : 0.028
# in : 0.018
# most : 0.016
# programming : 0.060 // <-- The third most important token
# languages : 0.062 // <-- The second most important token
# [SEP] : 0.047 // Filter out the [SEP] token
The resulting formula for the BM42 score would look like this:
向量数据存储
示例:JetBrains + Local Storage
JetBrains 在进行 IDE 搜索时支持 DiskSynchronizedEmbedding 的方式,从远程服务器下载向量向量数据,然后将其存储在本地文件系统中。 降低了对远程服务器的依赖,提高了性能和稳定性。
优势:
- 高效的读写操作。使用
RandomAccessFile进行随机访问,提供高效的读写能力,避免了将整个文件加载到内存中,提高了性能。 - 增量更新。仅更新需要更改的部分,而不是重写整个存储文件,从而提高了写入效率,减少了资源消耗。
- 内存使用优化。通过按需加载和写入数据,显著减少内存占用,非常适用于大规模向量向量存储场景。
- 磁盘持久化。通过 LocalEmbeddingIndexFileManager 实现磁盘持久化存储,确保数据的持久性和可靠性。支持从磁盘加载和保存索引,增强数据恢复能力。
- 便于管理和维护。将ID和向量向量分开存储,分别为JSON文件和二进制文件,便于管理和维护。
缺点:
- 本地存储限制。依赖本地存储空间,可能会受到硬件限制,如果向量向量数据量非常大,可能需要频繁监控和管理存储资源。
- 性能瓶颈。在高并发环境下,读写锁的争用可能成为性能瓶颈。极端情况下,可能会出现性能下降的问题,需要进一步优化和调整。
- 不支持分布式访问。由于数据存储在本地文件系统中,不支持跨服务器或分布式系统访问,限制了应用场景。
示例:Sweep + Redis
Our simple vector database implementation
优势:
- 管理多个索引的复杂性:
- 标准的向量数据库在处理单个索引时表现良好,但在管理多个索引、频繁更新和自托管时变得复杂。
- 使用 Redis 可以简化这一过程,无需管理多个索引和重建索引的问题。
- 基础设施和依赖管理:
- 使用外部存储(如 Pinecone)会引入额外的依赖和潜在的故障点。
- Redis 是一个流行的开源内存数据库,可以轻松自托管,减少了对外部服务的依赖。
- 缓存机制:
- Redis 非常适合缓存用途,可以快速读取和写入数据,这对于频繁访问的 Embedding 向量非常重要。
- 通过使用 Redis,系统可以缓存 Embedding 结果,减少对 OpenAI API 的调用次数,降低成本和延迟。
缺点:
- 该方法速度较慢(每个查询大约1秒),但满足他们的需求。
- 系统在超过 100 万个向量向量时扩展性不佳,但符合他们当前的需求(通常每个代码库文件少于30k)。
示例:通义灵码 + RocksDB
RocksDB 是一个开源的向量式键值存储引擎,由 Facebook 开发并开源。它在许多方面有着显著的优势:
- 高性能:RocksDB 被优化用于快速的随机读/写操作,适合需要高吞吐量和低延迟的应用场景。它支持并发操作,能够有效地处理大量的并发读写请求。
- 可调优性:RocksDB 提供了多种调优选项,允许用户根据具体的应用需求进行配置。例如,可以调整内存使用、写入策略、压缩算法等,以最大化性能和资源利用率。
- 持久性:RocksDB 具备持久化特性,即数据写入后可靠保存。这使得它非常适合作为后端存储引擎,支持需要持久化存储的应用程序。
- 可扩展性:RocksDB 的设计支持数据的水平扩展。它可以在多个节点上部署,通过分区和复制来实现数据的高可用性和可扩展性。
- 内存效率:RocksDB 能够有效地管理内存,尤其是对于大型数据集。它通过有效的缓存策略和紧凑的数据结构,降低了内存占用并提高了整体的效率。
- 灵活性:RocksDB 支持多种数据模型,包括键值对、列族存储等。这种灵活性使得它可以应用于各种不同类型的存储需求,从简单的键值存储到更复杂的列存储系统。
总体来说,RocksDB 在性能、可靠性和灵活性方面都表现出色,使其成为许多大型互联网公司和应用程序的首选存储引擎之一。
/Users/phodal/.lingma/tmp/cache/v3.3
├── 000001.vlog
├── 00001.mem
├── DISCARD
├── KEYREGISTRY
├── LOCK
└── MANIFEST
RocksDB 体积:
-rw-r--r-- 1 phodal staff 13M 13 Jul 11:04 librocksdbjni-linux-aarch64-musl.so
-rw-r--r-- 1 phodal staff 13M 13 Jul 11:02 librocksdbjni-linux-aarch64.so
-rw-r--r-- 1 phodal staff 16M 13 Jul 11:00 librocksdbjni-linux-ppc64le-musl.so
-rw-r--r-- 1 phodal staff 17M 13 Jul 11:00 librocksdbjni-linux-ppc64le.so
-rw-r--r-- 1 phodal staff 13M 13 Jul 11:09 librocksdbjni-linux-riscv64.so
-rw-r--r-- 1 phodal staff 15M 13 Jul 11:05 librocksdbjni-linux-s390x-musl.so
-rw-r--r-- 1 phodal staff 15M 13 Jul 11:05 librocksdbjni-linux-s390x.so
-rw-r--r-- 1 phodal staff 14M 13 Jul 05:39 librocksdbjni-linux32-musl.so
-rw-r--r-- 1 phodal staff 14M 13 Jul 04:49 librocksdbjni-linux32.so
-rw-r--r-- 1 phodal staff 14M 13 Jul 06:06 librocksdbjni-linux64-musl.so
-rw-r--r-- 1 phodal staff 14M 13 Jul 05:11 librocksdbjni-linux64.so
-rw-r--r-- 1 phodal staff 8.5M 13 Jul 04:28 librocksdbjni-osx-arm64.jnilib
-rw-r--r-- 1 phodal staff 9.9M 13 Jul 04:12 librocksdbjni-osx-x86_64.jnilib
-rw-r--r-- 1 phodal staff 8.0M 13 Jul 11:10 librocksdbjni-win64.dll
示例:Tabnine + Qdrant
RAG 是一种常见的人工智能框架,通过添加信息检索组件来提高LLM生成答案的准确性,该组件为模型的每个查询添加数据和上下文。 RAG 的实现包括两个组成部分:
- 索引建立:Tabnine 构建了 RAG 索引,以便快速有效地检索相关数据。这些索引用于代码完成和聊天,可以基于本地代码或全局代码,依赖于 IDE 工作空间或组织的全局代码库中的所有代码。
- 查询:对于 Tabnine 收到的每个用户查询(无论是显式还是隐式的),Tabnine 会从 RAG 索引中检索相关的代码上下文,并将其作为上下文添加到AI模型的提示中。结果是 Tabnine 提供了更准确的代码建议,更符合用户代码库的需求。
当涉及到 RAG 索引的内容时,可以按照以下目录进行总结:
- 索引类型:代码补全索引和聊天索引
- 索引范围:本地索引:基于每个开发者的IDE工作空间、全局索引:基于整个组织的代码库
- 被索引的文件类型:符合特定文件扩展名的文件、未列在 .ignore 或 .gitignore 中的文件、不包括特定扩展名的文件:"md", " yaml", "yml", "json", "lock", "xml", "gradle", "bash", "sh", "txt", "csv"
- 索引生命周期:本地代码补全和聊天上下文索引的创建和增量更新、连接到组织代码库的索引的定期更新
- 索引过程:向量向量应用于每个代码块、代码补全索引计算在开发者的本地机器上运行、聊天索引计算需要 GPU,在 Tabnine 服务器上执行
- 索引位置和持久化:持久化在最终用户本地机器上的向量数据库(qdrant)
- 与组织代码库连接的集成:与 GitHub、GitLab 或 Bitbucket 等主要 Git 托管平台的集成、保持现有权限模型,只允许用户访问其有权限的存储库
这些总结点可以帮助理解 RAG 索引的不同方面和实现方式。
示例:Neon serverless Postgres + pgvector
pgvector: 30x Faster Index Build for your Vector Embeddings
pgvector是Postgres中最受欢迎的向量相似性搜索扩展。向量搜索在语义搜索和检索增强生成(RAG)应用中变得越来越重要,增强了大型语言模型(LLMs)的长期记忆能力。
在语义搜索和RAG应用中,数据库包含LLM未训练过的知识库,被分成一系列文本或块。每个文本保存在一行,并与一个由向量模型(如OpenAI的ada-embedding-002或Mistral-AI的mistral-embed)生成的向量相关联。
向量搜索用于找到与查询向量最相似的文本。这通过将查询向量与数据库中的每一行进行比较来实现,这使得向量搜索难以扩展。因此,pgvector实现了近似最近邻(ANN)算法(或索引),通过对数据库的一个子集进行向量搜索以避免冗长的顺序扫描。
**Hierarchical Navigable Small World(HNSW)**索引是最有效的ANN算法之一。其基于图的多层结构设计用于数十亿行的向量搜索,使HNSW在大规模上极为快速和高效,因此成为向量存储市场中最受欢迎的索引之一。
HNSW的两个主要缺点
-
内存:HNSW索引比其他索引(如倒排文件索引IVFFlat)需要更多的内存。这个问题可以通过使用更大的数据库实例解决,但对于使用AWS RDS等独立Postgres的用户来说,可能会遇到因为索引构建而需要过度配置的问题。利用Neon的扩展能力,可以在构建HNSW索引时扩展,之后再缩减以节省成本。
-
构建时间:HNSW索引对于百万行数据集可能需要数小时的构建时间,这主要是由于计算向量间距离所花费的时间。pgvector 0.6.0通过引入并行索引构建解决了这一问题,使得索引构建速度提高了30倍。
并行索引构建的必要性
虽然HNSW索引支持更新,但在以下两种情况下需要重新创建HNSW索引:
- 希望加快查询速度并优化向量搜索时。
- 已有HNSW索引,但表中删除了向量时,可能会导致索引搜索返回假阳性,从而影响LLM响应质量和AI应用的整体性能。
向量模型
Massive Text Embedding Benchmark (MTEB) Leaderboard. 排名
FlagEmbedding
BAAI/bge-small-zh-v1.5
相关库
- FastEmbed is a lightweight, fast, Python library built for embedding generation.
- ONNX Runtime is a cross-platform inference and training machine-learning accelerator.
相关资源
BERTopic

示例代码:
from umap import UMAP
from hdbscan import HDBSCAN
from sentence_transformers import SentenceTransformer
from sklearn.feature_extraction.text import CountVectorizer
from bertopic import BERTopic
from bertopic.representation import KeyBERTInspired
from bertopic.vectorizers import ClassTfidfTransformer
# Step 1 - Extract embeddings
embedding_model = SentenceTransformer("all-MiniLM-L6-v2")
# Step 2 - Reduce dimensionality
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine')
# Step 3 - Cluster reduced embeddings
hdbscan_model = HDBSCAN(min_cluster_size=15, metric='euclidean', cluster_selection_method='eom', prediction_data=True)
# Step 4 - Tokenize topics
vectorizer_model = CountVectorizer(stop_words="english")
# Step 5 - Create topic representation
ctfidf_model = ClassTfidfTransformer()
# Step 6 - (Optional) Fine-tune topic representations with
# a `bertopic.representation` model
representation_model = KeyBERTInspired()
# All steps together
topic_model = BERTopic(
embedding_model=embedding_model, # Step 1 - Extract embeddings
umap_model=umap_model, # Step 2 - Reduce dimensionality
hdbscan_model=hdbscan_model, # Step 3 - Cluster reduced embeddings
vectorizer_model=vectorizer_model, # Step 4 - Tokenize topics
ctfidf_model=ctfidf_model, # Step 5 - Extract topic words
representation_model=representation_model # Step 6 - (Optional) Fine-tune topic represenations
)