AI 辅助软件工程:遗留系统重构与迁移
安全守护的遗留系统迁移
从模式上来说,遗留系统重构的过程可以简单分为:
- 理解现有业务
理解现有业务是遗留系统重构的第一步。这需要分析现有代码库,以获取系统的业务逻辑和结构。 - 设计与拆分模块
在理解现有系统的基础上,设计新的架构并拆分为更小的模块。 - 构建测试防护网
构建测试用例和覆盖率,以确保重构过程中的系统功能不被破坏。 - 代码重构以迁移
代码重构是将系统从旧平台或语言迁移到新的平台或语言时的重要步骤。 - 验证与测试
迁移后的系统需要经过充分的验证与测试,以确保其行为与原系统一致。- Testcontainers: 开源 Java 库,支持在 Docker 容器中运行集成测试,以确保系统在不同环境下的一致性。
- Applitools: 利用 AI 进行视觉回归测试,确保 UI 在代码变更后的视觉一致性。
- RestQA: 开源测试框架,支持记录和复用 API 请求,简化测试数据管理。
代码理解与分析
遗留系统的一大痛点是没有知道业务知识,所以在生成式 AI 的加持下,问题域可以变为:
- 如何结合从现有的代码中知道业务的实现。即结合语义化搜索与 RAG,将用户的查询转换为代码搜索,最后交由 AI 来总结。
- 如何可视化业务逻辑。在不同的场景之下,实现功能的要求也是不一样的。从可视化的角度来说,我们可以将代码转换为 DSL,再结合可视化工具来展示。
代码理解:基于 AI 的代码解释
遗留系统往往缺乏完整的文档和注释,理解这些代码对于开发者来说是一个巨大的挑战。AI工具能够通过代码解析与可视化技术,帮助开发者快速理解代码结构与逻辑。例如,IBM Watsonx Code Assistant for Z通过AI生成的解释和文档,帮助开发者更好地掌握系统的全貌。
代码可视化分析:基于活文档
如结合我们以往的工具,我们在 AutoDev 的文档生成功能中添加了活文档(Living Documentation)的功能,你可以结合注解从现有的逻辑中可视化业务。
如下是一个结合 AutoDev 生成活文档的示例:
@ScenarioDescription(
given = "a file with name $filename and program text $programText",
when = "the function tryFitAllFile is called with maxTokenCount $maxTokenCount, language $language, and virtualFile $virtualFile",
then = "the function should return an ErrorScope object with the correct values"
)
随后,就可以清晰地呈现已有的逻辑实现。
代码重构与转换
由于不同语言间存在一些能力等的差异,所以我们需要考虑到不同的语言的场景。诸如于,在 AutoDev 中针对于 PL/SQL 构建了相似的功能:
- 从 SQL 代码生成 entity 代码。
- 从 SQL 代码生成 Java 测试。
- 从 SQL 代码生成 Java 代码。
考虑到对于语言的理解,能力还是有待进一步完善的。
中间表示:结合 AST 工具的代码重构
https://research.google/blog/accelerating-code-migrations-with-ai/
多年来,谷歌一直使用专门的基础设施来执行复杂的代码迁移。该基础设施使用静态分析和如 Kythe 和 Code Search 等工具来发现需要更改的位置及其依赖关系。然后使用如 ClangMR (Clang’s refactoring engine)等工具进行更改。
ClangMR 示例:
class LocalRename final : public RefactoringAction {
public:
StringRef getCommand() const override { return "local-rename"; }
StringRef getDescription() const override {
return "Finds and renames symbols in code with no indexer support";
}
RefactoringActionRules createActionRules() const override {
...
}
};
Kythe, 这是一个可插拔的、(几乎)与语言无关的生态系统。它旨在帮助开发者构建与代码协同工作的工具。
print_classes() {
kythe ls --uris --files "kythe://kythe?path=$1" \
| parallel kythe refs --format "'@target@ @edgeKind@ @nodeKind@ @subkind@'" \
| awk '$2 == "/kythe/edge/defines" && $3 == "record" && $4 == "class" { print $1 }' \
| xargs kythe edges --targets_only --kinds /kythe/edge/named \
| awk '{ print substr($0, index($0, "#")+1) }' \
| parallel python -c '"import urllib, sys; print urllib.unquote(sys.argv[1])"'
}
print_classes kythe/java/com/google/devtools/kythe/analyzers/java/
print_classes kythe/cxx/tools/fyi/
经典转换工具
- OpenRewrite 是一种自动化代码重构工具,它致力于帮助开发者高效地消除其代码库中的技术债务。该系统通过智能化的重构功能,助力开发者提升代码质量。
- Lossless Semantic Trees 无损语义树的特点是不仅包括详细的类型信息以支持精确的代码匹配和转换,还保留了源代码的格式,以确保在重构时不会破坏原有的代码风格。
测试生成与验证
AI 生成单元测试
传统的 API 记录?工具,记录测试数据,让 AI 自动验证
示例
IBM Watsonx Code Assistant for Z
IBM watsonx™ Code Assistant for Z 是一款生成式人工智能辅助产品,旨在以低于当前替代方案的成本和风险,加速大型机应用的现代化进程。
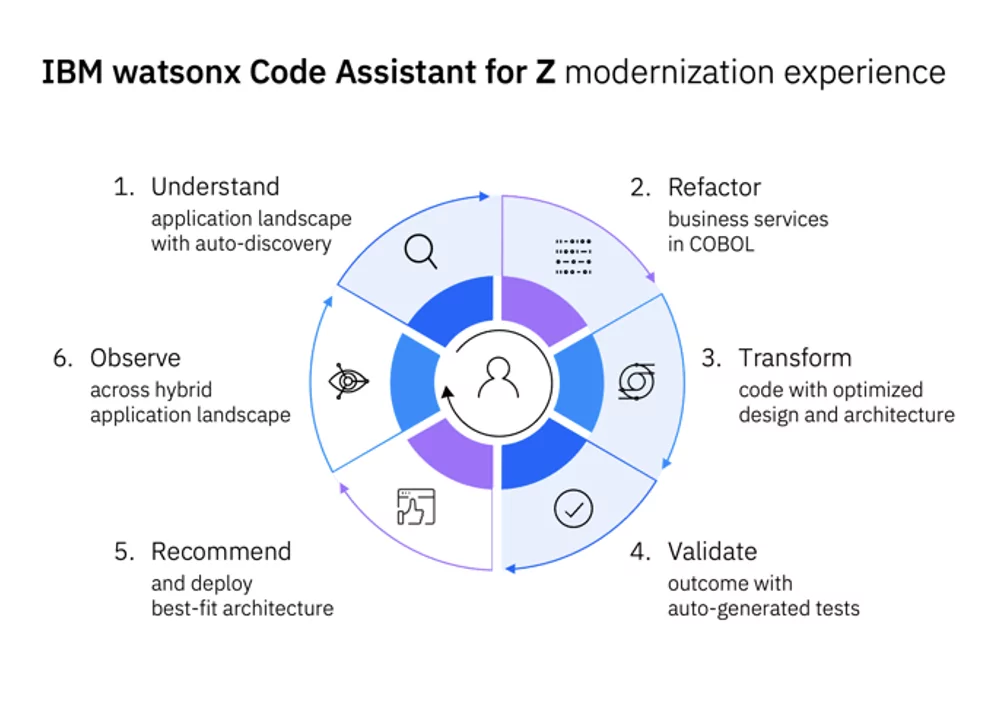
watsonx Code Assistant for Z 为开发者提供了一个端到端的应用开发生命周期,包括应用发现与分析、自动化代码重构、COBOL 到 Java 的转换、 自动化测试生成以及代码解释等功能。开发者可以自动重构应用中的选定元素,继续在 COBOL 中进行现代化,或者利用高度优化的先进大型语言模型, 通过生成式人工智能有选择地将代码转换为 Java。
- 理解。深入了解您的主机应用程序,并可视化它们之间的关系与依赖。利用生成式人工智能对代码进行解释,自动记录您的COBOL应用程序,帮助新程序员快速上手。
- 重构。发现程序及数据,以自动重构您的应用程序,将其转化为更独立业务服务,推动功能增强并提高可维护性,同时为COBOL的选转型至Java做好准备。
- 转换。利用生成式人工智能,在几分钟内而非数月内加速高质量的COBOL至Java转换。
- 验证。简化并加速新Java代码的测试过程,确保其与COBOL代码在语义上等效,以提高质量和降低风险。
- 推荐。推荐并部署最适合的架构。
- 观测。在混合应用/混合云环境中进行观测。
Moderne
LSTs
---
type: specs.openrewrite.org/v1beta/recipe
name: com.yourorg.VetToVeterinary
recipeList:
- org.openrewrite.java.ChangePackage:
oldPackageName: org.springframework.samples.petclinic.vet
newPackageName: org.springframework.samples.petclinic.veterinary
高层次的LST解释
为了在不引入语法或语义错误的风险下程序化地修改代码,必须使用一种能够准确且全面表示代码的数据结构。OpenRewrite使用无损语义树(LSTs)来实现这一目的。 像其他树形数据结构一样,更复杂的LST是递归地由其他更简单的LST组成的。
例如,一个ClassDeclaration是一个定义类的LST。一个典型的类声明将由诸如字段、方法、构造函数和内部类等元素组成。这些元素本身也是LST。因此, "LST"这一术语可以指代整个完整的Java文件,也可以只是文件中的一部分。
需要注意的是,操作LSTs可能会导致生成无法编译的代码。虽然OpenRewrite在其类型系统中提供了一些防护措施(例如,不允许将import语句替换为方法声明), 但仍然可能编写出符合Java语法但不能作为有效可编译程序的代码。
无损语义树:提升 LLM 代码准确性
在深入了解 Moderne 如何具体整合 AI 之前,让我们先探讨一些关于利用AI进行基于规则的自动重构的技术思考和细节。
大多数 LLM(大型语言模型)是基于自然语言和源代码文本进行训练的,并没有考虑自然语言和代码之间的区别。代码有其结构、严格的语法和一个可以确定性解析它的编译器, 这些特性是可以被利用的。
一些研究已经尝试对模型进行微调,使用像 AST(抽象语法树)、CST(具体语法树)、数据流、控制流甚至程序执行等结构化代码表示。然而, 基于这些模型的AI调优将需要时间(和计算能力!)。此外,这些树缺乏关于代码的语义数据,例如类型分配,而这些数据对于准确的代码库搜索至关重要。
目前,像聊天机器人这样的业务应用使用了一种称为检索增强生成(RAG)的技术来增强LLM的训练。RAG 通过使用嵌入从相关外部来源获取数据, 来提高生成 AI 模型的准确性和可靠性,指导模型的决策过程。向量允许我们为模型提供上下文,包括它未曾接受过训练的数据,以及比实时 IDE 上下文窗口提供的更多文本。
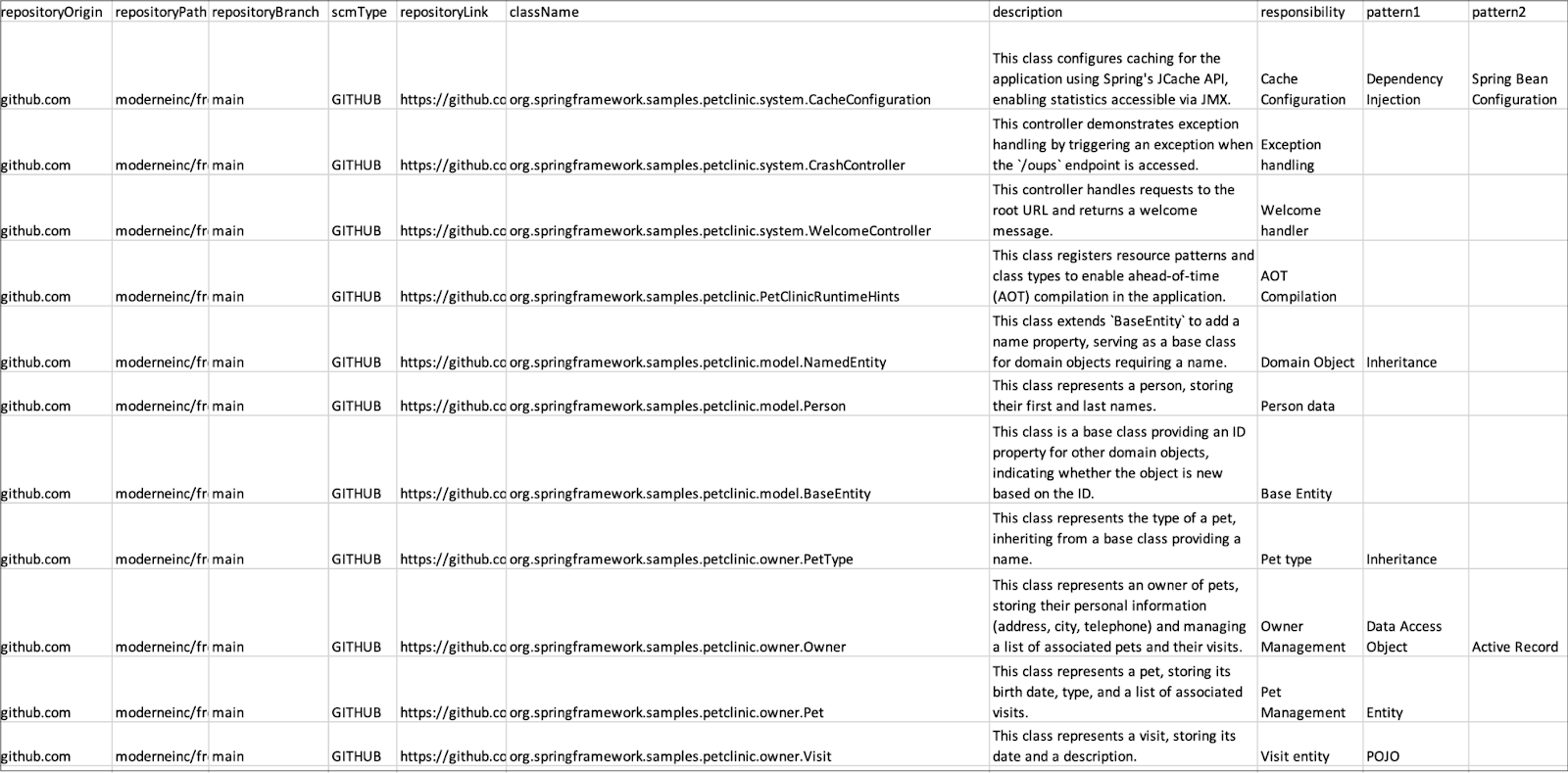
在处理大型代码库时,我们也需要一种方法来从用户的代码库中检索相关数据作为上下文,并将其与查询一起输入 LLM。幸运的是,通过 OpenRewrite 自动重构开源项目, 我们获得了一种新的代码表示形式——无损语义树(LST),它包括类型分配和其他元数据。这种全保真度的代码表示形式是准确搜索和转换代码的基础——它可以像嵌入一样在自然语言文本中发挥作用。 此外,Moderne 平台将 LST 序列化到磁盘,使其水平扩展,从而将重构工作从单一仓库模式扩展到多仓库模式。
Moderne 平台通过聚合 LST,使我们能够查询大型代码库,并将结果提供给LLM进行查询或生成。然后,我们可以使用我们的100%准确的重构系统验证 LLM 的建议。
总而言之,对于代码处理,Moderne 可以利用 LST 为 LLM 提供高度相关的上下文,这些LST是你代码的极其丰富的数据表示。我们使用开源 LLM 在我们的平台上安全地部署这一解决方案, 确保没有代码离开这个环境。此外,通过我们的平台,我们可以有效地测试并选择适合特定任务的最佳 LLM。
在OpenRewrite规则基础上的AI LLM集成
Moderne 平台在预构建和缓存的 LST(无损语义树)上运行 OpenRewrite 规则(或程序),以搜索和转换代码。这使我们能够在多个代码库中执行规则,提供近乎实时的反馈,以进行实时代码分析。
在创建规则时,提供了许多声明性格式以便于使用,但用户也可以开发自定义编程规则以获得最大灵活性。还可以实现多种类型的集成,例如自定义的 OpenRewrite 规则。 一个这样的例子是 LaunchDarkly 特性标志移除,它调用 LaunchDarkly 来识别未使用的特性标志,从代码库中移除特性标志下的功能,然后再次调用 LaunchDarkly 来删除未使用的特性标志。 一个规则还可以包装和执行其他工具,例如我们在JavaScript codemods集成中的应用。
LLM(大型语言模型)是我们可以集成到规则中的另一个重要工具,以支持新的和有趣的用例。我们专注于可以在 CPU 上运行的开源专用 LLM, 以在Moderne 平台内实现最大操作安全性和效率。这使我们能够在与规则处理 LST 代码表示形式的相同基于 CPU 的工作节点上配置这些模型。 通过测试和评估各种从Hugging Face下载的模型,我们可以识别最佳模型,并随着每天新模型的到来不断迭代选择。模型的选择可能会影响任务的准确和快速完成与否。
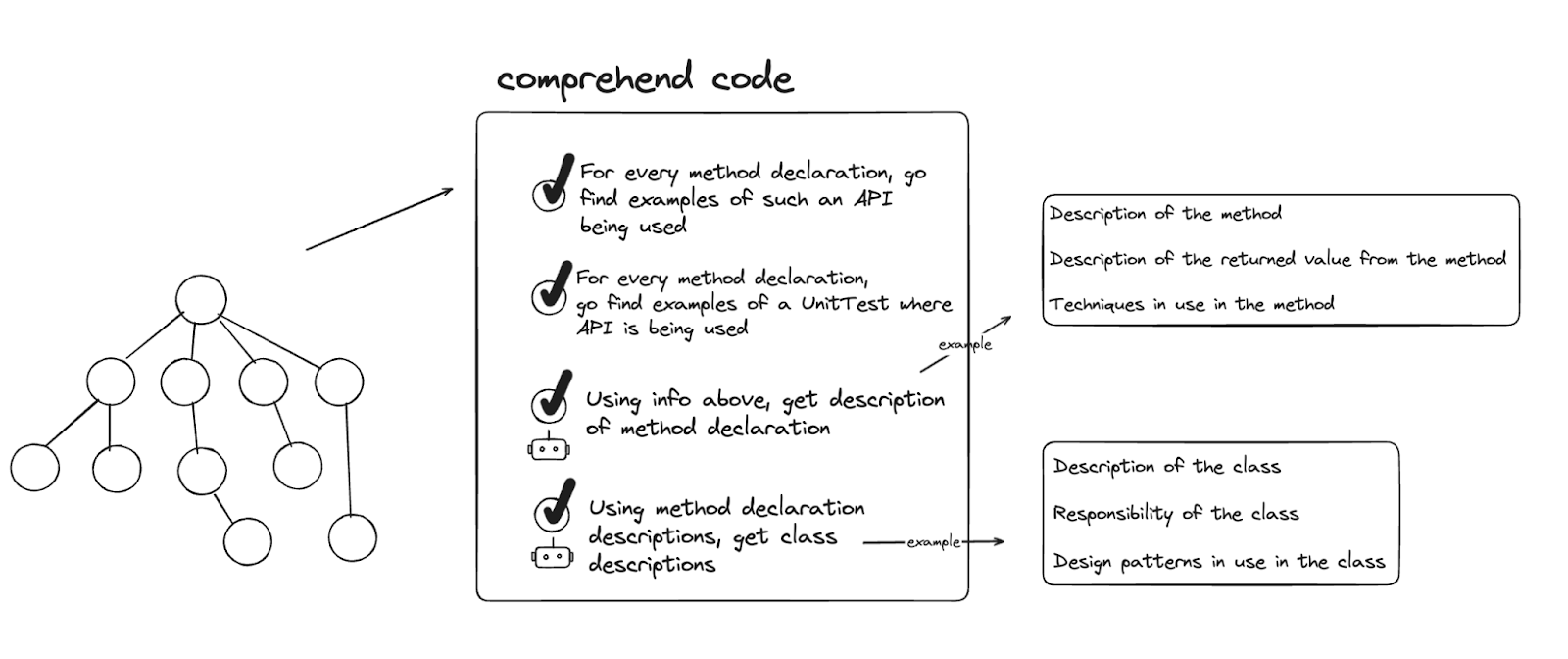
当规则在工作节点上运行时,它可以在LST中搜索所需的数据,将其传递给适当的LLM,并接收响应。LST仅将需要评估或转换的部分发送给模型。规则然后将LLM响应插入回LST中。 Moderne平台生成差异供开发者审查,并提交回源代码管理(SCM),确保模型以精准的方式完成其任务。参见图1中的流程。
Bloop
State of Mainframe Modernization
转换 HumanEval 数据集
构建评估工具:COBOLEval
IDENTIFICATION DIVISION.
PROGRAM-ID. HAS-CLOSE-ELEMENTS.
ENVIRONMENT DIVISION.
INPUT-OUTPUT SECTION.
DATA DIVISION.
LINKAGE SECTION.
01 LINKED-ITEMS.
05 L-NUMBERS OCCURS 100 TIMES INDEXED BY NI COMP-2.
05 L-THRESHOLD COMP-2.
05 RESULT PIC 9.
* Check if in given list of numbers, are any two numbers closer to each other than
* given threshold.
* >>> has_close_elements([1.0, 2.0, 3.0], 0.5)
* False
* >>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3)
* True
*
* Complete the WORKING-STORAGE SECTION and the PROCEDURE DIVISION
* Store the result in the RESULT variable and mark the end of your program with END PROGRAM
WORKING-STORAGE SECTION.
SourceGraph Cody示例
资料来源:A simpler way to understand legacy code
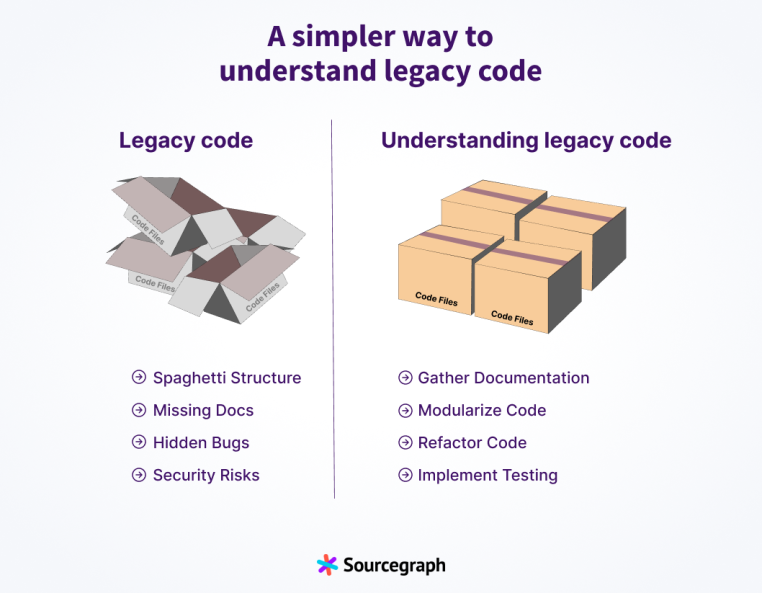
这篇文章介绍了构建遗留系统重构的过程和策略,并提供了一些实用工具来帮助开发人员理解和改进遗留代码。
主要流程和策略如下:
- 评估代码库:
- 设置开发环境并运行代码以确保其按预期工作。
- 使用代码静态检查工具(如ESLint或Pylint)来识别语法错误和潜在问题。
- 使用依赖关系分析工具和架构可视化工具来了解项目的依赖关系和结构。
- 文档和注释:
- 利用现有的文档和注释来获取代码的原始目的、设计决策和潜在问题的洞察。
- 对缺乏文档的遗留系统进行文档补充和注释更新。
- 代码分析工具:
- 使用静态分析工具(如SonarQube、PMD、CAST)来识别代码问题、代码异味和安全漏洞。
- 这些工具还能揭示代码依赖关系和结构,帮助开发人员确定重构的优先级。
- 版本控制历史:
- 利用版本控制系统(如Git)来理解代码库的历史,通过分析提交日志来追踪代码的变更。
- 使用
git blame和git log命令来了解每行代码的最后修改情况及其原因。
- 重构和清理:
- 在不改变外部行为的前提下对代码进行重构,以提高代码的可维护性和可读性。
- 采用小规模、可管理的更改,使用特性分支并持续测试代码,以验证重构未影响功能。
- 测试和验证:
- 编写单元测试、集成测试和端到端测试来验证更改,防止回归问题。
- 在没有测试的遗留代码上编写测试,以确保代码可靠性。
使用Cody的辅助工具:
Cody是一款AI编程助手,旨在帮助开发人员理解、编写、审查和重构代码,并加速代码生成和软件开发。它的主要功能包括:
- 自动完成:利用大语言模型(LLM)提供代码预测和建议,支持多种编程语言。
- 聊天功能:回答与代码相关的技术问题,并提供上下文答案。
- 命令功能:运行预定义操作并创建自定义命令以加速日常编码任务。
通过这些功能,Cody可以帮助开发人员理解遗留代码结构,识别潜在问题,并提出改进建议。
使用Cody的实际示例:
- 重构代码:Cody可以识别代码异味并建议改进。
- 编写单元测试:Cody可以生成单元测试代码,帮助验证代码的预期行为。
- 生成文档:Cody可以自动生成代码文档,帮助未来的协作者理解代码。
总结:
通过评估代码库、利用文档、使用代码分析工具、理解版本控制历史、谨慎重构和全面测试,开发人员可以有效地理解和改进遗留代码。AI编程助手如Cody能够进一步简化这些过程,提供有价值的见解和自动化支持,使处理遗留系统变得更容易和高效。
Moderne Moddy
源:https://chat.deepseek.com/a/chat/s/586a0da9-afb2-4740-bd7b-5627703fb2e4
有了 Moddy,开发人员可以轻松浏览、分析并修改庞大且复杂的代码库。想象一下,只需简单的查询,Moddy 就能帮助你:
- 描述当前代码库中的依赖关系
- 升级框架
- 修复安全漏洞
- 定位特定的业务逻辑
Moddy 不只是另一个 AI 代码助手。与现有 AI 工具主要针对单个存储库代码生成或重构不同,Moddy 可一次性处理整个代码库,包括数十亿行代码。
Moderne 的核心技术是 Lossless Semantic Tree(LST)数据模型,它超越了传统的 “代码即文本” 和 抽象语法树(AST) 方法。LST 数据类似于 IDE 内部代码表示,但更进一步,能够捕获 代码结构、依赖关系和多存储库间的联系。Moderne 还可以 序列化 LST 数据,为 AI 提供代码库的关键上下文,使 Moddy 能够在大规模场景下高效进行现代化改造、安全增强和代码分析。
Moddy 如何在大规模场景下运行?
LST 代码数据是 Moddy 强大能力的基础,但技术突破远不止于此。以下是一些关键能力,使 Moddy 能够**实时处理海量代码数据,并提供前所未有的准确性、速度和洞察力 **。
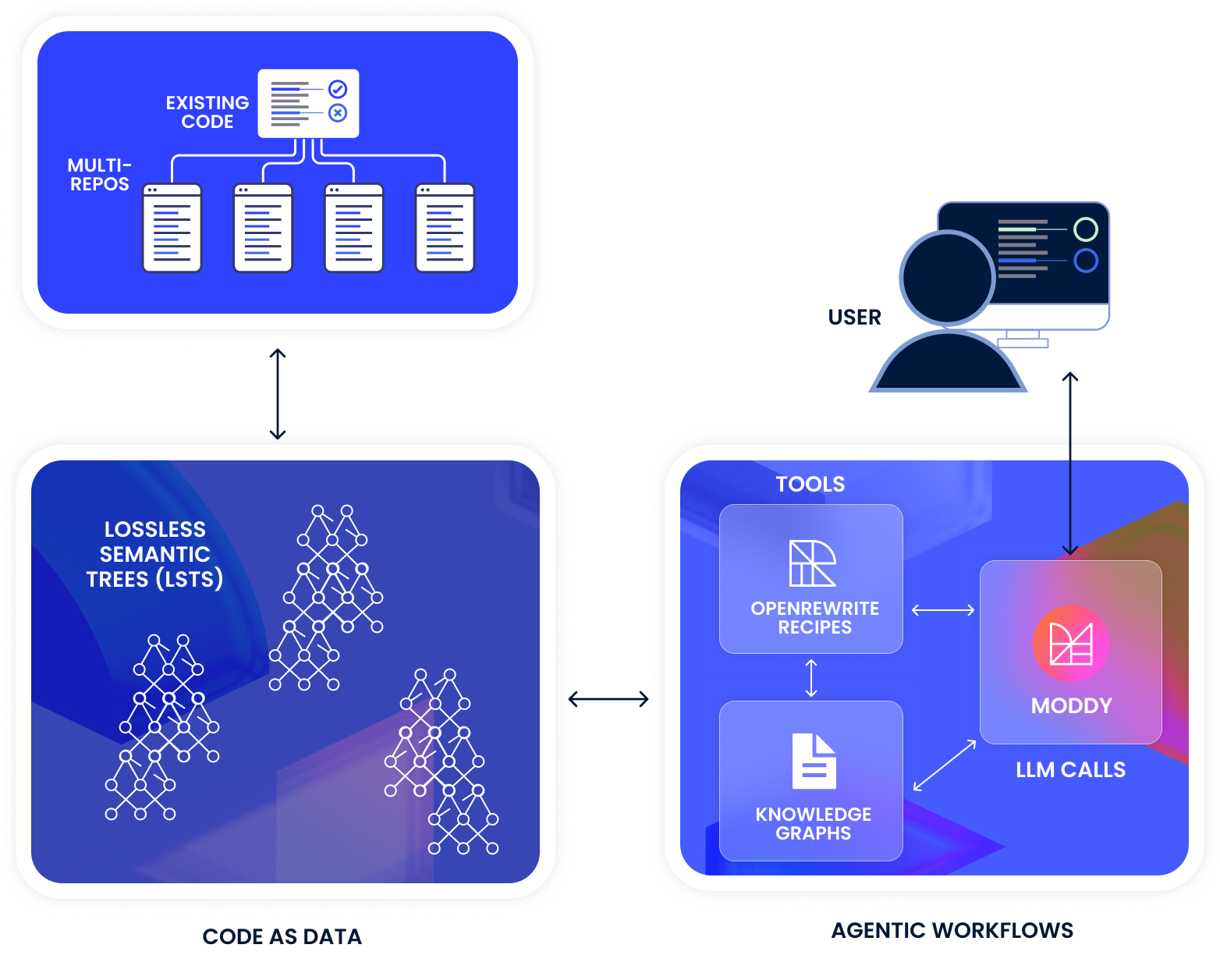
1. OpenRewrite 规则变为 AI 的工具
2024 年底,工具函数调用(Tool Calling) 技术的突破,使 Moderne 实现了一种混合方法,将 LLM 与确定性规则(recipes)结合。
- Moddy 通过 Langchain 调用 OpenRewrite 规则,让 LLM 具备执行代码库级变更的能力。
- Moddy 能够自动选择合适的工具(规则),执行任务并将结果整合到 AI 反馈中。
2. 知识图谱:让 LLM 更智能
基于 LST 数据,可以构建 知识图谱 作为 LLM 的附加数据源。例如:
- 按架构模式搜索代码(如响应式代码或数据库事务相关代码)。
- 按业务功能搜索代码(如支付处理相关代码)。
- 生成 API 文档(使用 UpdateReadme 规则 )。
- 自动绘制架构图,帮助团队更好地理解代码结构。
3. 编译验证:AI 代码变更的质量保障
许多 AI 助手的代码变更流程是 “AI 修改代码 → 运行构建工具检查编译 → AI 修正错误”,这导致验证过程既耗时又**计算成本高 **。
Moderne 研发了一套 编译验证规则,可以在 代码变更后迅速反馈是否可编译,且计算成本极低。Moddy 通过该规则 **即时评估代码修改质量 **,确保大规模代码变更的安全性和可行性。联系 Moderne 代表,申请 独家 Beta 测试。解锁你的代码库潜力,与 Moddy 一起,引领软件开发的未来! 🚀