SQL 生成
度量
Text2SQL 榜单:Spider
示例
Full Rag:Hyperpersonalization 应用
Tecton的方法:
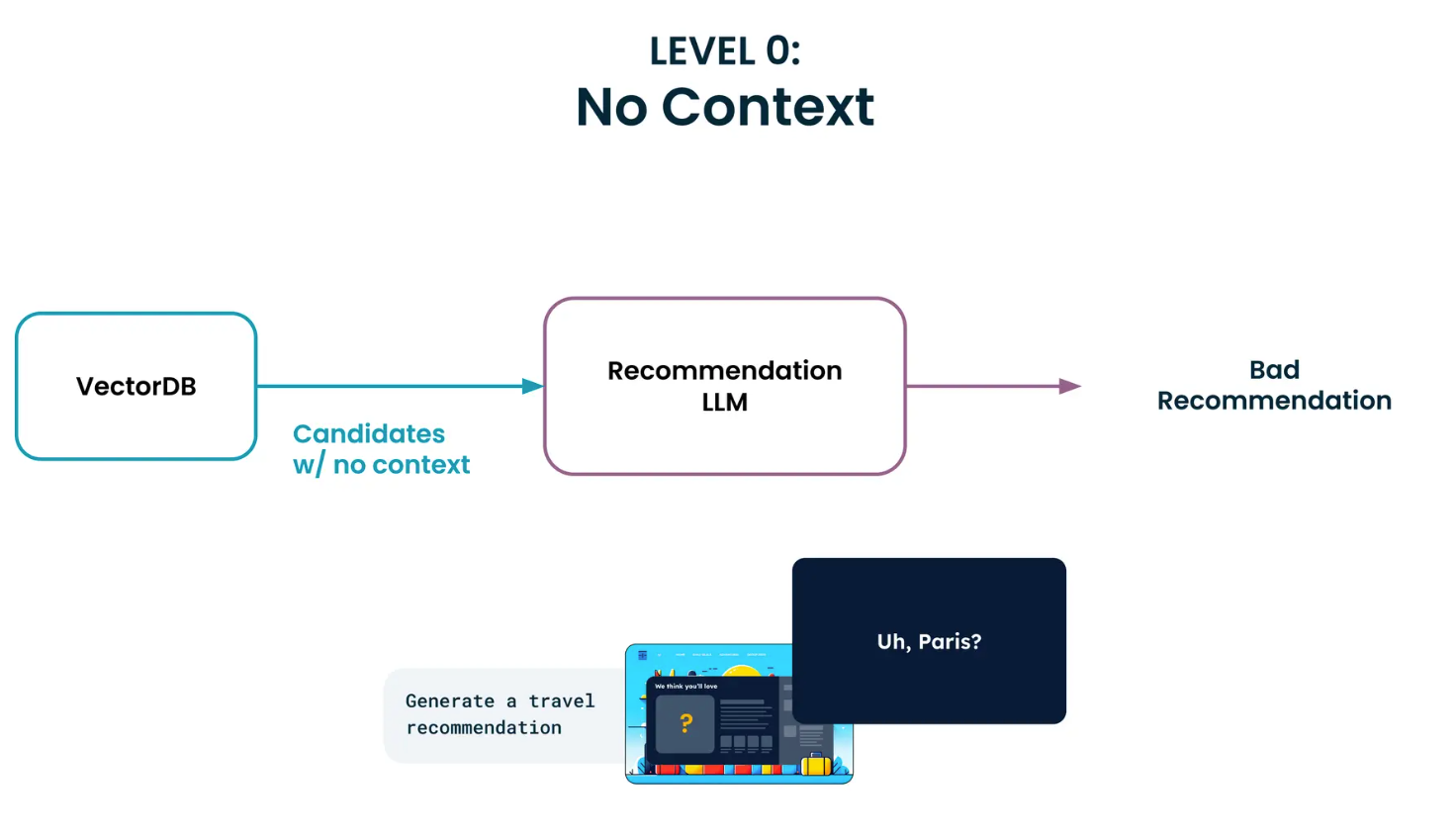
- 基础层(Level 0): 仅限于基本的检索,没有额外的上下文信息。
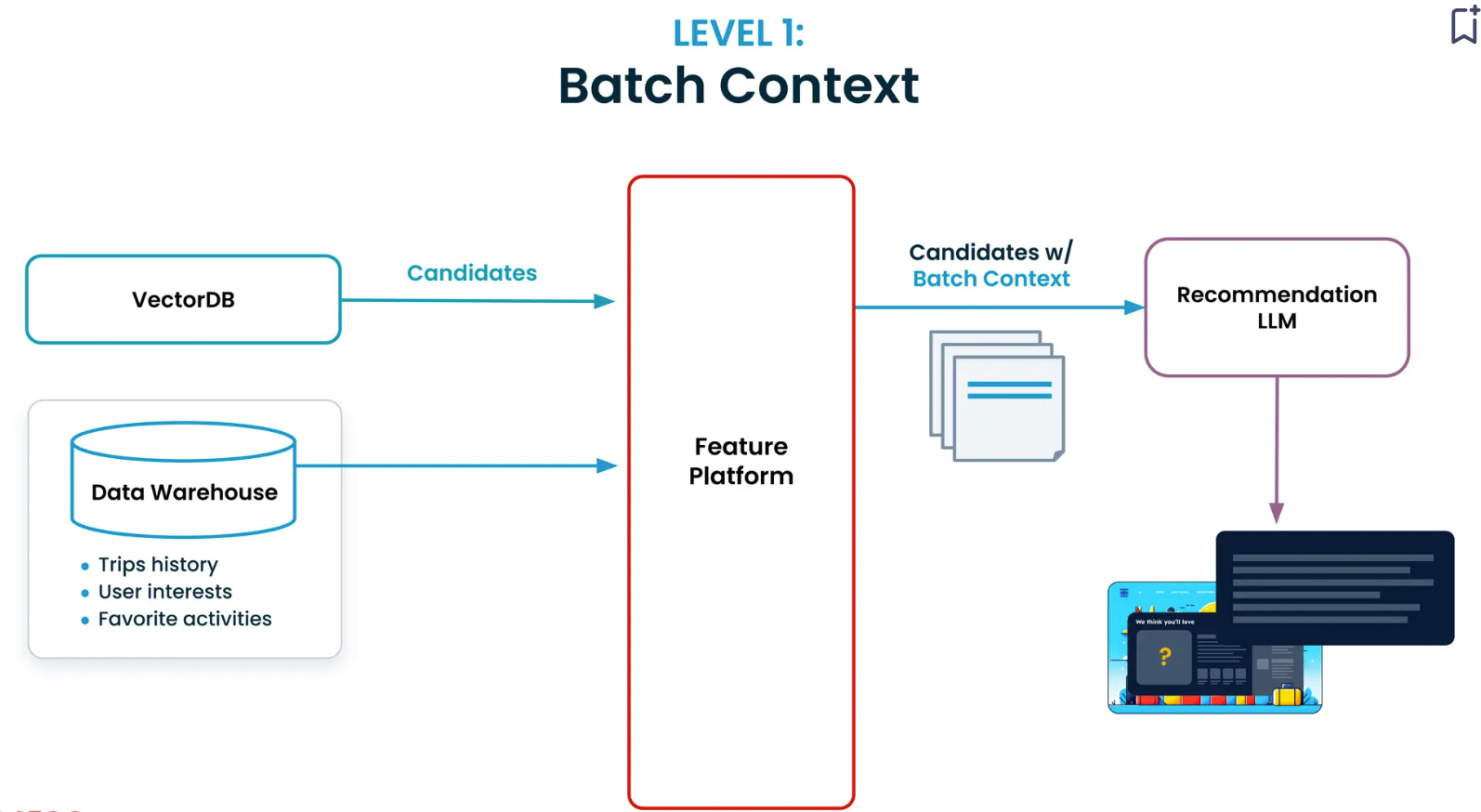
- 批处理上下文(Level 1): 使用历史数据(例如之前的旅行记录、喜爱的活动)。Tecton通过管理数据管道和历史数据集来简化构建此类上下文的过程。
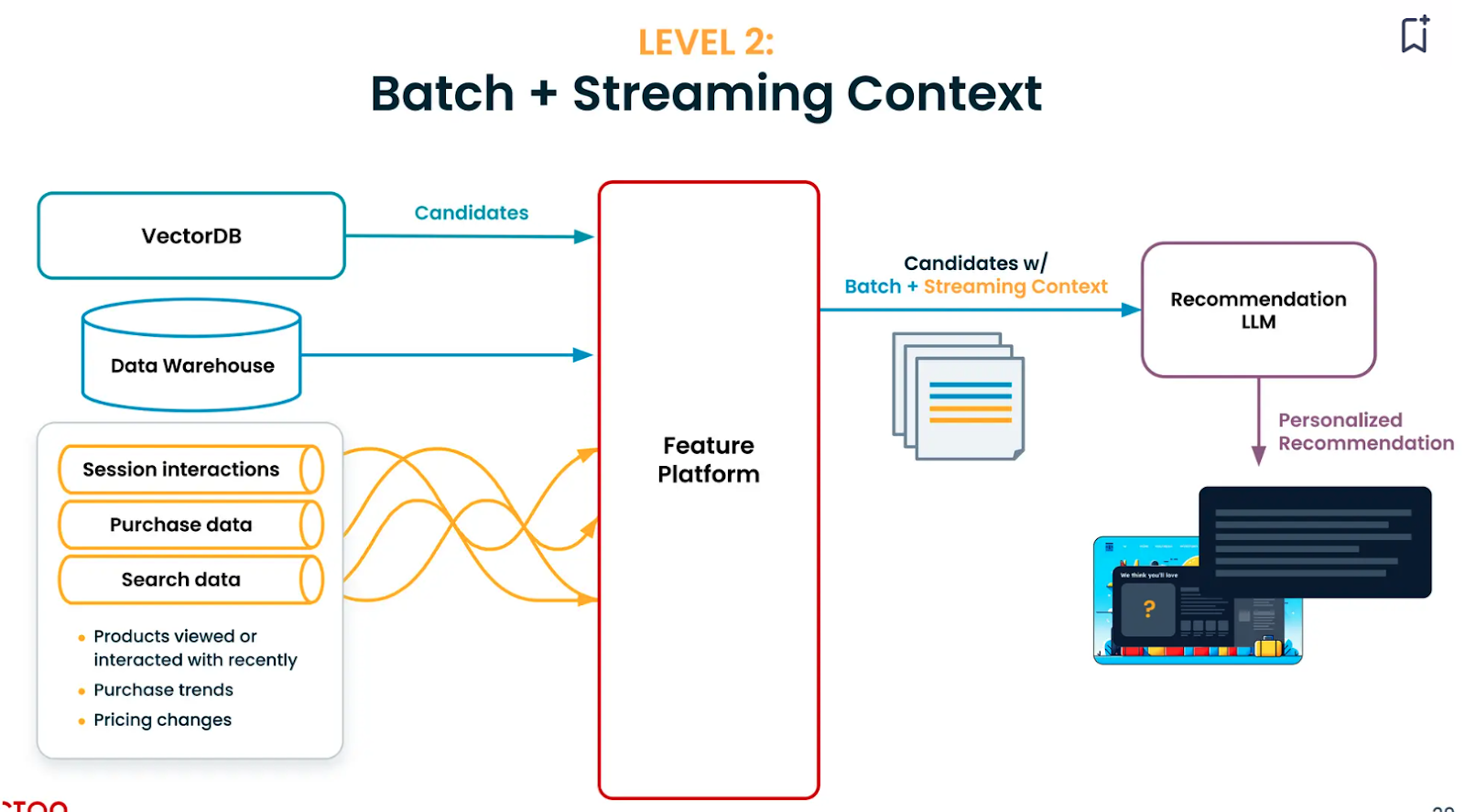
- 批处理 + 流数据上下文(Level 2): 整合实时用户数据(例如最近的搜索、会话交互)。这一阶段提供更及时的推荐,但实施成本较高。
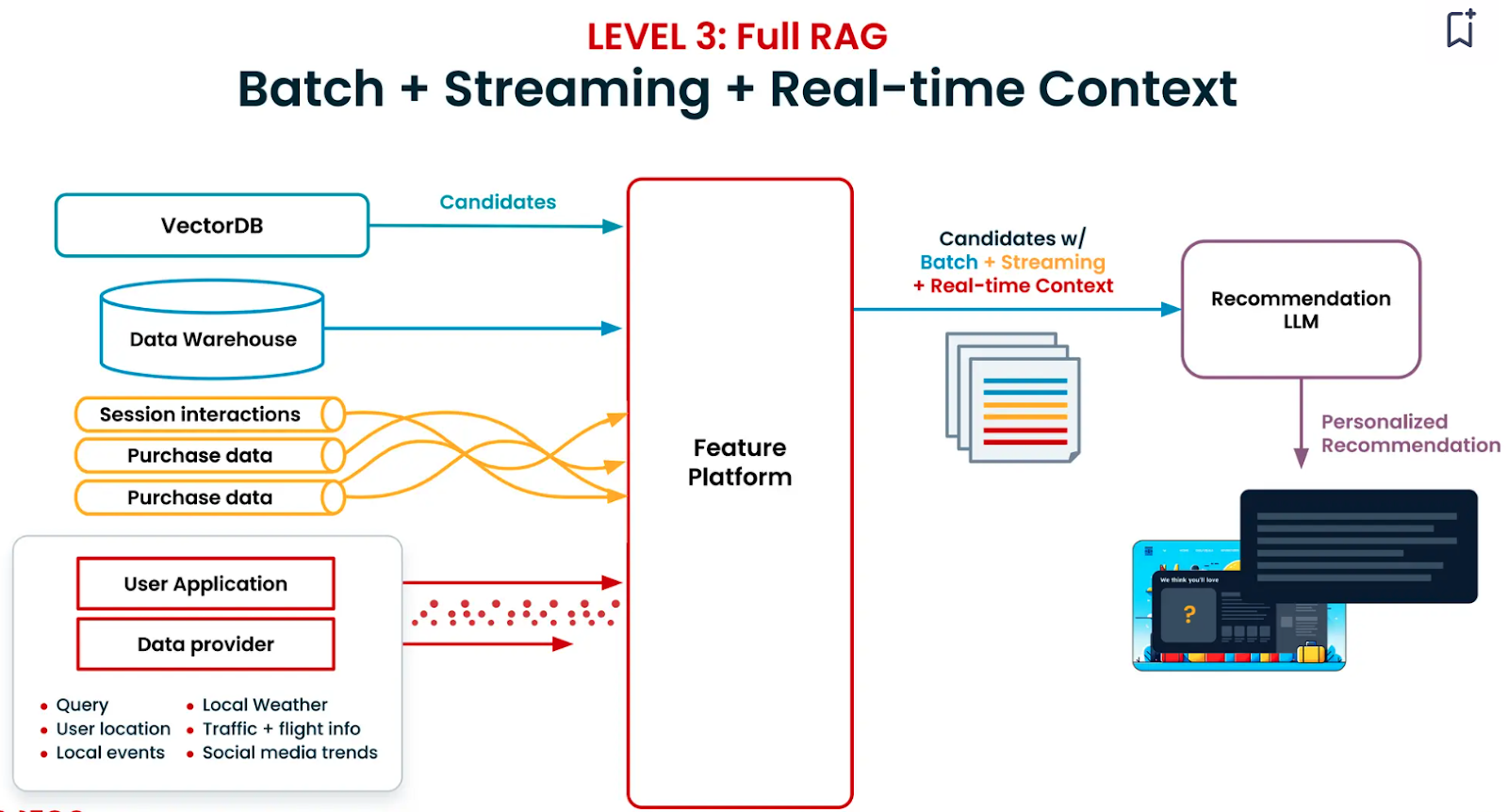
- 批处理 + 流数据 + 实时上下文(Level 3): 引入实时数据,如实时搜索查询和应用程序互动。挑战包括整合第三方数据源以及平衡速度与成本。这一层级提供高度相关的实时推荐,还可以包括基于反馈的调整。
Level
RAG2SQL:Vanna
Vanna is an MIT-licensed open-source Python RAG (Retrieval-Augmented Generation) framework for SQL generation and related functionality.
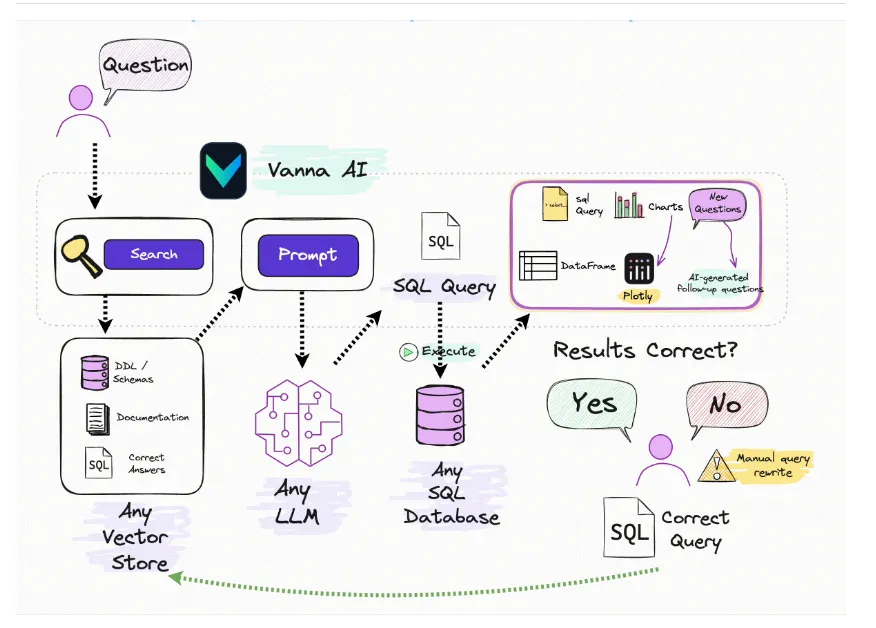
Vanna: The Supercharged Text-to-SQL Tool All Data Scientists Were Looking For
Function RAG
Function RAG(检索增强生成) 是 Vanna.ai 引入的一项创新功能,旨在改进 SQL 生成。以下是详细说明:
什么是 Function RAG?
Function RAG 将传统的“问题-SQL”对转换为可重用的模板或函数,这些模板由大语言模型(LLM)调用以生成 SQL 查询和相关的后处理代码(如图表代码)。LLM 的作用是选择合适的 SQL 模板并填充必要的参数,从而实现更一致且更快速的 SQL 生成。
Function RAG 的主要特点:
- 基于模板的 SQL 生成:通过使用从训练对创建的模板,Function RAG 确保生成的 SQL 既准确又相关。
- 增强的安全性:这种方法减少了提示注入和提示转义等漏洞,使 SQL 生成过程更加安全。
- 用户特定查询:用户可以在查询中包含特定信息,如用户 ID,且不会有数据被覆盖的风险,从而安全地实现个性化查询。
- 集成图表代码生成:Function RAG 可以在一次请求中生成 SQL 及相应的可视化代码(如 Plotly 代码)。
- 多语言支持:通过 GraphQL API 访问,Function RAG 可以在各种编程语言中使用,不仅限于 Python,便于集成到不同的后端,如 Ruby on Rails、.NET 等。
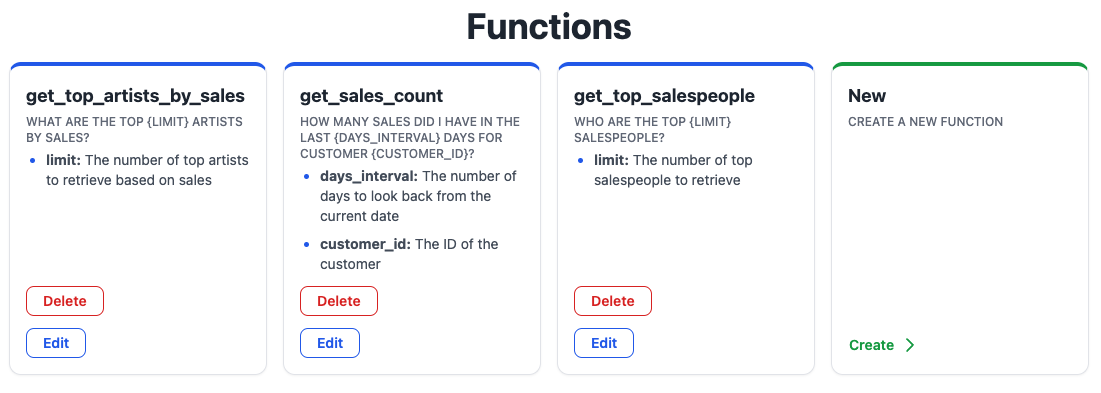
使用示例:
- 查找函数:使用
vn.get_function(question=...)查找并调用适当的函数,由 LLM 填充参数。 - 限定到特定用户:使用
vn.get_function(question=..., additional_data={"user_id": ...})确保查询限定到特定用户,通过确定性地设置user_id参数。 - 创建新函数:可以手动使用
vn.create_function(question=..., sql=..., plotly_code=...)创建函数,或者通过支持自动从问题中提取参数的 Web 应用创建函数。
何时使用 Function RAG:
Function RAG 适用于终端用户频繁提出类似问题的场景。它允许进行受控和批准的分析,确保呈现的数据可靠且正确。此功能特别适合内部业务用户或
SaaS 应用程序。然而,对于更多新颖和多样的分析,传统的 SQL 生成功能可能更合适。
Uber QueryGPT
QueryGPT – Natural Language to SQL Using Generative AI
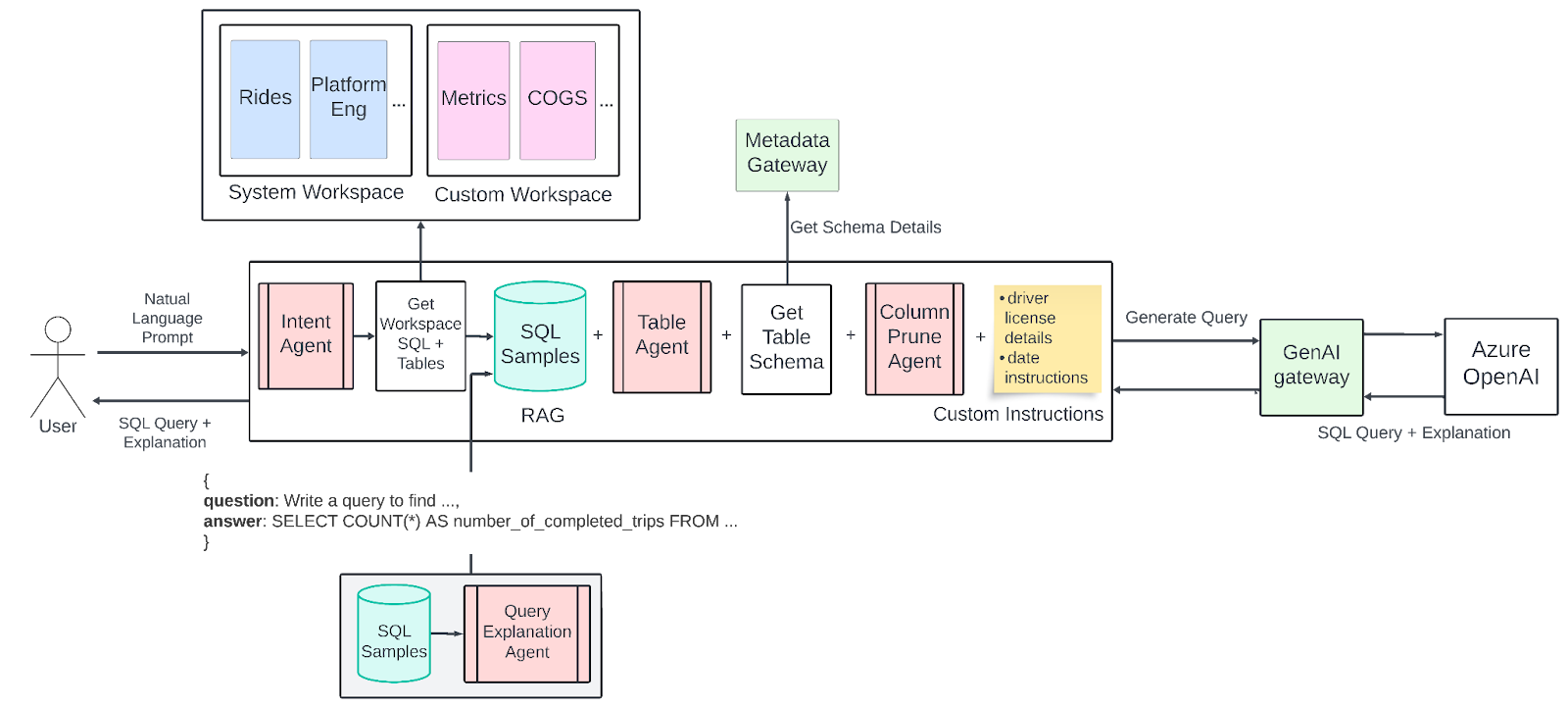
Uber 开发了 QueryGPT,一个可以使用自然语言提示生成 SQL 查询的工具。
核心目标
该工具旨在通过简化 SQL 查询的编写过程来提高生产力,因为传统的 SQL 查询需要深入了解 SQL 语法和 Uber 的内部数据模型。
工作原理
QueryGPT 利用 大语言模型(LLM)、向量数据库 和 相似性搜索,将用户的英语问题翻译成复杂的 SQL 查询。
据估算,该工具将 SQL 查询的编写时间从 约 10 分钟缩短到了 3 分钟。
开发历程
QueryGPT 最初是在 2023 年 5 月 Uber 的生成式 AI 黑客马拉松 上提出的,并经过 20 多次迭代 才发展到当前的架构。
最初的版本使用 RAG(检索增强生成) 系统来获取相关的 SQL 示例和表结构信息。其流程如下:
- 用户输入自然语言查询
- 系统向量化输入,然后进行相似性搜索以检索相关的 SQL 代码片段和表结构
- LLM 结合这些信息,生成 SQL 查询
开发背景
Uber 的数据平台每月要处理 约 120 万个交互式查询,其中 运营部门贡献了约 36%。
通过自动化 SQL 查询的生成过程,QueryGPT 使非 SQL 专家也能高效访问和操作数据,极大地优化了工作流。
总结
QueryGPT 代表了 Uber 在数据可访问性上的一次重大突破。它能将 自然语言输入 转换为 可执行 SQL 查询,从而提升整体效率和生产力。
Text to SPL
<data-source> | <spl-expr> ... | <spl-expr> ...
SPL 即 SLS Processing Language,是 SLS 对日志查询、流式消费、数据加工、Logtail 采集、以及数据 Ingestion 等需要数据处理的场景,提供的统一的数据处理语法,这种统一性使得 SPL 可以在整个日志处理的生命周期内,实现 "Write Once,Run Anywhere" 的效果。
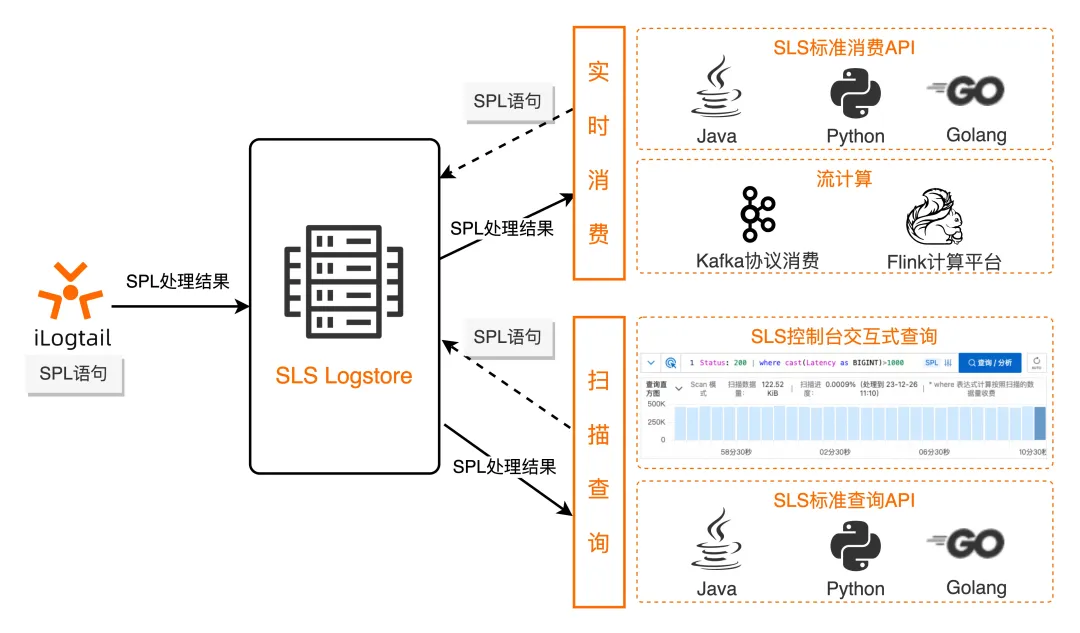
<spl-expr> 是 SPL 指令,支持正则取值、字段分裂、字段投影、数值计算等多种操作,具体参考 SPL 指令介绍。
示例:
Status:200 | extend urlParam=split_part(Uri, '/', 3)
Status:200 | extend timeRange = cast(BeginTime as bigint) - cast(EndTime as bigint
示例 2:
Status:200
| where UserAgent like '%Chrome%'
| extend timeRange = cast(BeginTime as bigint) - cast(EndTime as bigint)
| where timeRange > 86400